Coverage hangover.

That’s what sets in after we’re done hitting all the easy stuff and move on to targeting the more obscure corners of a coverage model. The pace slows. Progress slows. We have lots of review meetings to debate the merits of coverpoints, some of which we may not even understand. Through trial-and-error we plod along as best we can until someone says whatever we have is good enough (because 100% coverage is impossible). Then we shrug our shoulders, add a few exclusions, write up a few waivers, shake off the hangover and move on.
I’ve had coverage hangover several times. I’m sure we all have. With some devices – the really massive SoCs – there are verification engineers that live through coverage hangover for months at a time. Their only reprieve, if you can call it that, tends to be bug fixing. If they’re lucky, they’ll get to implement a new feature now and then. Otherwise, it’s a cycle of regression, analysis, tweak and repeat.
The worst part of a coverage hangover is that the next hangover is guaranteed to be worse because the next device is always bigger. At least that’s what happens with current verification strategies. I’d like to propose we break common practice with a reset. Regrettably, it won’t change the fact that coverage space will continue to grow. But it will give some relief for the next few generations while folks smarter than me find better ways to define, collect and analyze coverage.
In closing coverage, our focus and timing have always struck me as being out of tune with the reality of the mission. I’m proposing we change that by breaking coverage into a series of steps that we can focus on independently, moving from one type to the next as features mature. Continue reading →

 Verification engineers have a habit of over-engineering testbenches and infrastructure. We can all admit that, no? I can certainly admit it. From first hand experience, I can also admit that the testbenches I’ve over-engineered had a lot of waste build into them; unnecessary features I forced people to use and features that were never used at all. And there’s no good reason for it other than I like building new testbench features. Don’t think I’m alone there.
Verification engineers have a habit of over-engineering testbenches and infrastructure. We can all admit that, no? I can certainly admit it. From first hand experience, I can also admit that the testbenches I’ve over-engineered had a lot of waste build into them; unnecessary features I forced people to use and features that were never used at all. And there’s no good reason for it other than I like building new testbench features. Don’t think I’m alone there.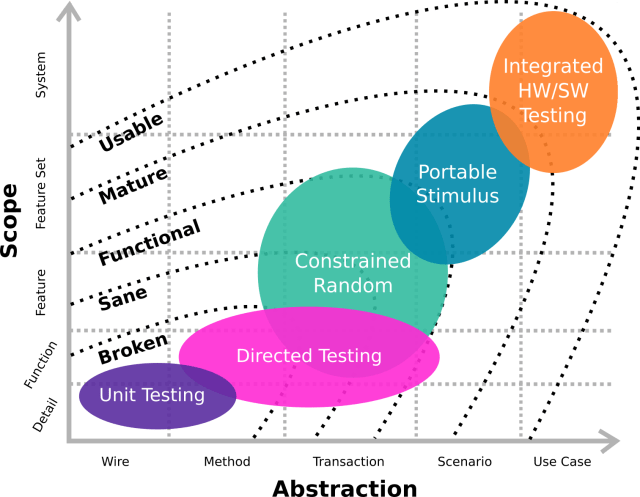

 A 2017 Toyota 4Runner costs $44,440; that’s the TRD PRO model with the roof rack and alloy wheel options. Because my aversion to spending money is stronger than my love for dream vehicles, I’ve decided I can’t afford that. But I’d still like to drive one so I have to find a way other than paying for one myself. I think I found it…
A 2017 Toyota 4Runner costs $44,440; that’s the TRD PRO model with the roof rack and alloy wheel options. Because my aversion to spending money is stronger than my love for dream vehicles, I’ve decided I can’t afford that. But I’d still like to drive one so I have to find a way other than paying for one myself. I think I found it…